Section 1 reproduces the data and the plot you sent me, just so that you can be reassured that we are on the same page to start off with
Section 2 attempts to answer the questions you raised in the email
Section 3 My preferences and suggestions
Section 4 shows data in groups of 116 in case you want to look at them
Section 5 Summary and remarks
The table that follows, table 1.1, is copied from your email,and reproduced here. The only change is that I have used 4 decimal point precision for all values other than counts
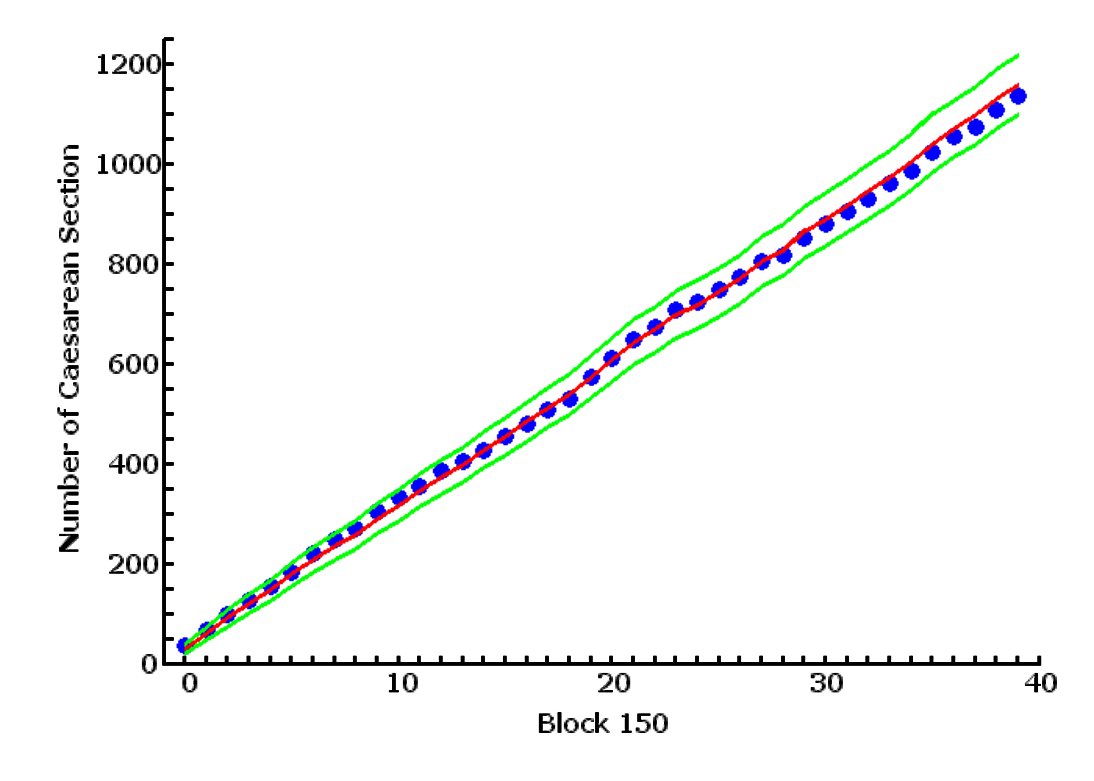
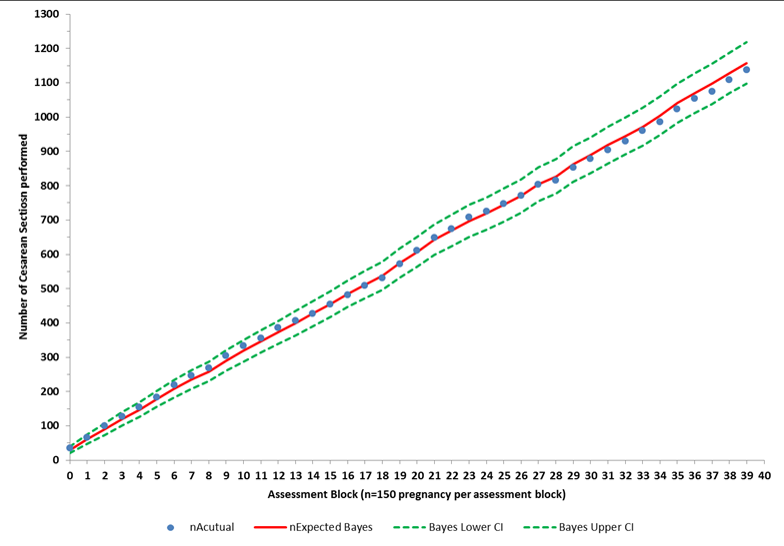
The two plots, fig. 1.1 and 1.2 reproduced the plot you sent me. The one on the left, 1.1 is produced by me from the data in table 1.1, and the plot on the right is copied directly from your email. The two plots are the same except for slight differences in color, dot size, and line thickness.
At this point, we can be reassured that we are discussing the same data
| Group | Cum | nAcutual | nExpected Bayes | Bayes LowerCI | Bayes Upper CI | nExpectedLogReg | LogReg Lower CI | LogRegUpperCI |
|---|---|---|---|---|---|---|---|---|
| 0 | 150 | 35 | 30.0427 | 20.4356 | 39.6498 | 29.2703 | 19.7570 | 38.7836 |
| 1 | 300 | 66 | 61.1432 | 47.4679 | 74.8185 | 58.5732 | 45.1165 | 72.0299 |
| 2 | 450 | 100 | 91.0563 | 74.3524 | 107.7602 | 88.5474 | 72.0178 | 105.0771 |
| 3 | 600 | 127 | 120.1444 | 100.9317 | 139.3571 | 117.9996 | 98.9167 | 137.0825 |
| 4 | 750 | 155 | 147.4112 | 126.0807 | 168.7417 | 144.8026 | 123.6160 | 165.9893 |
| 5 | 900 | 184 | 178.1732 | 154.7432 | 201.6032 | 175.3873 | 152.0964 | 198.6782 |
| 6 | 1050 | 219 | 208.7142 | 183.3682 | 234.0602 | 205.4788 | 180.2817 | 230.6759 |
| 7 | 1200 | 247 | 235.0856 | 208.1378 | 262.0334 | 231.3200 | 204.5368 | 258.1032 |
| 8 | 1350 | 269 | 257.9118 | 229.6009 | 286.2227 | 253.8190 | 225.6811 | 281.9570 |
| 9 | 1500 | 305 | 290.5922 | 260.5910 | 320.5934 | 285.3762 | 255.5814 | 315.1710 |
| 10 | 1650 | 334 | 318.5043 | 287.0817 | 349.9269 | 313.3368 | 282.1098 | 344.5638 |
| 11 | 1800 | 356 | 346.0408 | 313.2721 | 378.8095 | 340.9109 | 308.3286 | 373.4931 |
| 12 | 1950 | 387 | 372.6766 | 338.6463 | 406.7069 | 367.9176 | 334.0544 | 401.7809 |
| 13 | 2100 | 406 | 398.8202 | 363.5904 | 434.0500 | 393.4699 | 358.4222 | 428.5176 |
| 14 | 2250 | 427 | 427.7556 | 391.2747 | 464.2365 | 421.9667 | 385.6759 | 458.2574 |
| 15 | 2400 | 454 | 455.3973 | 417.7476 | 493.0470 | 449.3335 | 411.8770 | 486.7899 |
| 16 | 2550 | 481 | 484.8436 | 446.0050 | 523.6822 | 479.1713 | 440.5076 | 517.8350 |
| 17 | 2700 | 509 | 512.3191 | 472.3857 | 552.2525 | 506.0471 | 466.3020 | 545.7922 |
| 18 | 2850 | 531 | 537.8418 | 496.8997 | 578.7839 | 530.4738 | 489.7484 | 571.1992 |
| 19 | 3000 | 572 | 574.0483 | 531.8193 | 616.2773 | 566.3344 | 524.3235 | 608.3453 |
| 20 | 3150 | 611 | 607.2679 | 563.8727 | 650.6631 | 598.7302 | 555.5689 | 641.8915 |
| 21 | 3300 | 649 | 643.1103 | 598.5109 | 687.7097 | 633.9194 | 589.5633 | 678.2754 |
| 22 | 3450 | 675 | 669.6481 | 624.1158 | 715.1804 | 659.3933 | 614.1277 | 704.6589 |
| 23 | 3600 | 708 | 697.5983 | 651.1161 | 744.0805 | 686.4501 | 640.2524 | 732.6478 |
| 24 | 3750 | 725 | 718.6158 | 671.3759 | 765.8557 | 707.1926 | 660.2414 | 754.1437 |
| 25 | 3900 | 748 | 744.2691 | 696.1698 | 792.3684 | 733.3583 | 685.5304 | 781.1862 |
| 26 | 4050 | 772 | 769.6905 | 720.7527 | 818.6283 | 758.7847 | 710.1142 | 807.4552 |
| 27 | 4200 | 804 | 804.2861 | 754.3054 | 854.2668 | 792.3041 | 742.6096 | 841.9985 |
| 28 | 4350 | 816 | 827.4272 | 776.6924 | 878.1620 | 815.6115 | 765.1558 | 866.0672 |
| 29 | 4500 | 853 | 862.8551 | 811.0945 | 914.6157 | 850.5715 | 799.0939 | 902.0490 |
| 30 | 4650 | 879 | 888.9808 | 836.4240 | 941.5376 | 875.8127 | 823.5554 | 928.0700 |
| 31 | 4800 | 904 | 918.3476 | 864.9346 | 971.7606 | 904.2225 | 851.1254 | 957.3195 |
| 32 | 4950 | 929 | 944.7783 | 890.5867 | 998.9699 | 930.1867 | 876.3174 | 984.0560 |
| 33 | 5100 | 961 | 972.0906 | 917.1125 | 1027.0687 | 956.8774 | 902.2308 | 1011.5239 |
| 34 | 5250 | 986 | 1003.7453 | 947.8994 | 1059.5912 | 987.4182 | 931.9220 | 1042.9144 |
| 35 | 5400 | 1024 | 1040.4681 | 983.6622 | 1097.2740 | 1023.4508 | 967.0015 | 1079.9001 |
| 36 | 5550 | 1054 | 1070.2851 | 1012.6769 | 1127.8933 | 1052.7310 | 995.4853 | 1109.9766 |
| 37 | 5700 | 1075 | 1096.9988 | 1038.6620 | 1155.3356 | 1078.3642 | 1020.4081 | 1136.3203 |
| 38 | 5850 | 1109 | 1128.8365 | 1069.6779 | 1187.9951 | 1109.6596 | 1050.8866 | 1168.4326 |
| 39 | 6000 | 1137 | 1157.6948 | 1097.7842 | 1217.6054 | 1138.4851 | 1078.9559 | 1198.0142 |